Issues with Code Quality Metrics
This article is a spin-off piece from the paper "Do We Need Improved Code Quality Metrics?" by myself and Prof. Diomidis Spinellis.
Software metrics have always been on a roller-coaster ride. On one hand, researchers and practitioners have adopted metrics not only to reveal quality characteristics of their programs, but also to combine existing metrics into new ones, and use these to study more complex phenomena. On the other hand, metrics have drawn wide criticism. The majority of this criticism is related to completeness and soundness.
The first case covers the extent of completeness of the implementation details provided to compute the metrics independent from the programming language. For instance, implementation details of metrics in C&K suite are missing, leaving it up to one's interpretation. Two examples of such deficiencies involve the lack of concrete details for the implementation of the lack of cohesion in methods (LCOM) metric, and the incomplete definition of the coupling between objects (CBO) metric. Particularly, the definition of the CBO metric does not clarify whether both incoming and outgoing dependencies or only outgoing dependencies should be used in the calculation.
Soundness of a metric refers to the ability of the metric to accurately capture the notion underlying its theoretical basis. Shepperd and Ince presented their critical view on the Halstead, cyclomatic complexity, and information flow metrics. They wrote that the computing rules followed in the Halstead metrics are arbitrary and make use of magic numbers without providing sufficient theoretical foundation. For instance, programming time T is computed through the formula T = E/(f * S), where E is referred to as programming effort, fas seconds-to-minute ratio = 60, and S as Stround number = 18. Furthermore, these metrics use tokens and number of operators and operands, which are considered too simplistic and primitive, because they fail to capture control, data, and module structure. Finally, Shepperd and Ince pointed out that Halstead metrics were developed in the era of batch processing where software systems were of a considerably smaller scale than today-often amounting to a few hundred lines of code. Similarly, other metrics such as cyclomatic complexity and maintainability index are also criticized for poor theoretical basis and validation.
A sound metric computing mechanism not only depends on the implementation, but also on the crisp definition of the metric [Fenton1997]. From the implementation perspective, different metric tools often produce different results for the same source code [Sharma2018]. More importantly, a metric is deprived from its usefulness if it does not measure what it intends to, especially in commonly occurring cases. SonarQube, a widely used platform to measure and track code quality metrics and technical debt, identified that cyclomatic complexity fails to represent ``complexity'' of a snippet correctly (for instance, in the presence of switch-case statements). The platform has recently introduced a new metric, i.e., cognitive complexity, as an alternative to the cyclomatic complexity metric.
Similarly, despite the availability of many variants (LCOM1, LCOM2, LCOM3, LCOM4, LCOM5, the lack of cohesion in methods (LCOM) metric is another example where the intended characteristic, i.e., cohesion, is not always correctly captured.
Apart from the issues of the existing metrics reported above, the following concerns are also identified regarding the commonly used code quality metrics. First, the present set of code quality metrics is mainly designed for object-oriented programs. Nowadays the software development community extensively uses programming languages, such as Python and JavaScript, that are not strictly object-oriented. Hence, the present set of metrics is not applicable in its original form on such languages. Second, the focus of code quality metrics has been limited to methods and classes. There is hardly any metric at the level of architecture granularity. For instance, akin to a complex method (inferred by using cyclomatic complexity metric), it is difficult to comment anything about the complexity of a component or the entire software system. Finally, recently, sub-domains of software, including tests and configuration code have become inseparable parts of the production code. The present set of metrics hardly support these sub-domains. Metrics such as code coverage for configuration and database code, as well as coupling between the test or infrastructure code and the production code could provide useful insight for the development community.
A survey: Opinions of software developers
We designed a questionnaire to be used in an online survey to gather the opinions of software developers and researchers. We received 78 complete responses belonging to different experience groups.
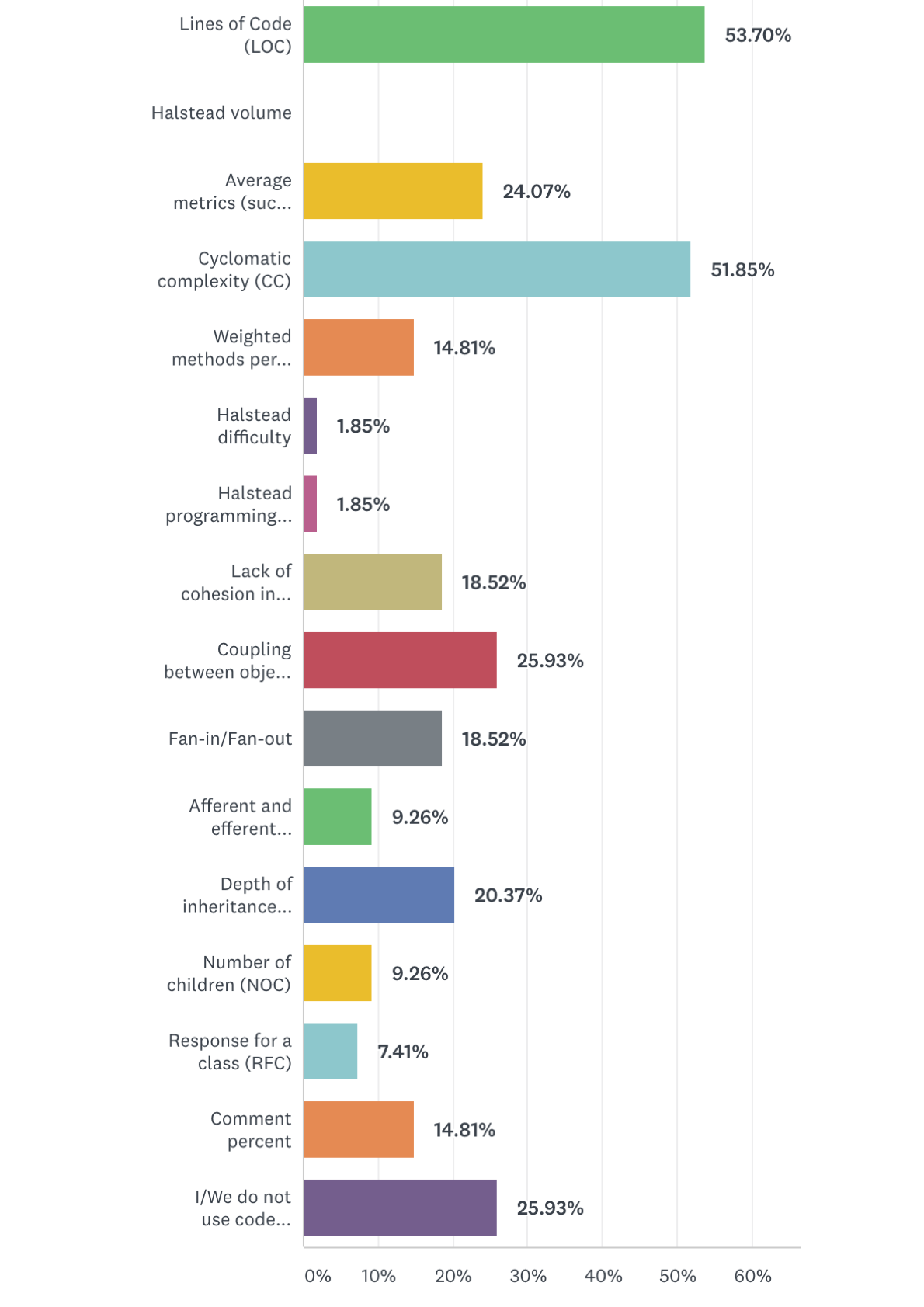
In the one of the questions, respondents were asked to choose from a list of commonly used code quality metrics, which ones they use and monitor on a regular basis. As expected, lines of code (LOC) and cyclomatic complexity (CC) are the most commonly used metrics; 54\% and 52% of the participants selected them, respectively. Almost none of the participants use Halstead metrics. Apart from the provided options, participants further mentioned that they rely on test coverage and clone percentage. Still, 26% of the participants affirmed that they do not use any metrics.
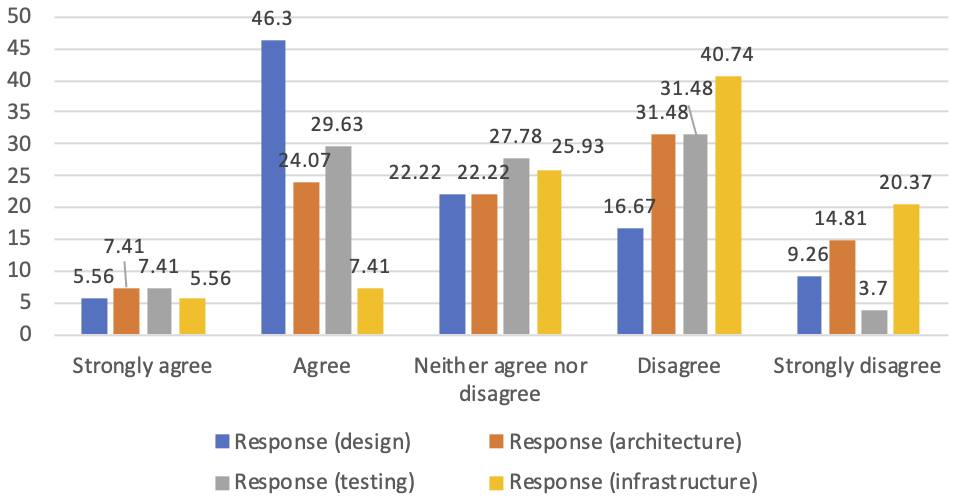
Next, respondents were asked whether the current set of metrics provides sufficient insight regarding software design. The majority (46% agree and 6% strongly agree) of the participants acknowledged that they get insight about software design using the current set of metrics. We asked a similar question about software architecture, and the majority (31% disagree and 15% strongly disagree) of the participants stated that the current set of code quality metrics is inadequate to measure quality of software architecture.
The next question inquired whether code quality metrics provide sufficient insight for the sub-domains of software development testing and infrastructure. Regarding the testing sub-domain, participants seemed divided. The majority (31% disagree and 4% strongly disagree) of the participants stated that code quality metrics fall short with respect to testing. The negative opinion was amplified for the infrastructure sub-domain. A clear consensus emerged among 61% (41% disagree and 20% strongly disagree) of the participants who supported that code quality metrics are insufficient to provide insight regarding infrastructure. Undoubtedly, a lot of progress is expected toward measuring infrastructure code quality.
An additional question was included regarding metrics showing inaccurate values due to wrong implementation and specification of the applied algorithm. 32% of the participants agreed that they often see inaccurate metric values due to wrong implementation of the metric tools. Another 39% of the participants did not notice any incorrect metric values.
I invite you to take a look at our paper for more details.
